


什么是Robots.txt?
Robots.txt是一个文件,它告诉搜索引擎蜘蛛不要抓取网站的某些页面或部分。大多数主要的搜索引擎(包括Google、Bing和Yahoo)都会识别并尊重Robots.txt请求。
为什么Robots.txt很重要?
大多数网站不需要robots.txt文件。
这是因为Google通常可以找到并索引你网站上所有的重要页面。
而且他们不会自动索引那些不重要的页面或其他页面的重复版本。
有3个使用robots.txt文件的理由:
- 阻止非公共页面被抓取:有时你的网站上有一些你不希望被索引的页面。例如,你可能有一个页面的暂存版本。或者是一个登录页面。这些页面是需要存在的。但你不希望随机的人登陆到这些页面上。在这种情况下,你会使用robots.txt来阻止这些页面被搜索引擎爬虫和机器人抓取。
- 最大限度地提高爬行预算:如果你很难让所有的页面都被索引,那么你可能有爬行预算问题。通过使用robots.txt阻止不重要的页面,Googlebot可以将更多的爬行预算花在真正重要的页面上。
- 防止资源类文件的索引:使用meta指令可以像Robots.txt一样防止页面被索引。然而,元指令对于多媒体资源(如PDF和图片)来说,效果并不好。这就是Robots.txt发挥作用的地方。
一句话:robots.txt会告诉搜索引擎蜘蛛不要抓取你网站上的特定页面。
你可以在Google站长工具中检查你有多少页面被索引。
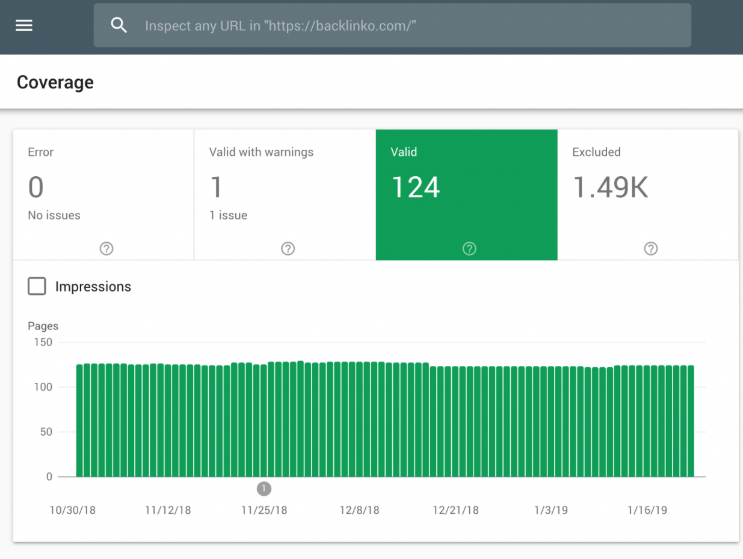
如果这个数字与你希望被索引的页面数量相匹配,那么你就不需要再费心建立Robots.txt文件了。
但如果这个数字比你预期的要高(而且你注意到了不应该被索引的URL),那么是时候为你的网站创建一个robots.txt文件了。
最佳做法
创建一个Robots.txt文件
你的第一步是实际创建你的robots.txt文件。
作为一个文本文件,你实际上可以使用Windows记事本创建一个。
无论你最终如何制作robots.txt文件,格式都是一样的。
User-agent: X
Disallow: Y
User-agent是你具体的搜索引擎爬虫。
而 “disallow “后面的所有内容都是你要屏蔽的页面或目录。
下面是一个例子:
User-agent: googlebot
Disallow: /images
这个规则会告诉Googlebot不要索引你网站的图片。
你也可以使用星号(*)来告诉所有搜索引擎爬虫停止在你的网站上爬取。
例如:
User-agent: *
Disallow: /images
“*”告诉任何和所有蜘蛛不要抓取你的图片。
这只是许多使用robots.txt文件的方法之一。这个来自Robots.txt是一个文件有更多的信息,你可以使用不同的规则来阻止或允许搜索引擎爬虫抓取你的网站的不同页面。

让你的robots.txt文件更容易找到
一旦你有了robots.txt文件,是时候让它活起来了。
技术上来说,你可以把robots.txt文件放在网站的任何主目录下。
但为了增加robots.txt文件被发现的几率,我建议把它放在以下位置:
https://example.com/robots.txt
注意,你的robots.txt文件是区分大小写的。因此,请确保在文件名中使用小写的 “r”)
检查是否有错误和错误
你的robots.txt文件的设置是否正确是非常重要的。一个错误,你的整个网站可能会被取消索引。
幸运的是,你不需要希望你的代码设置正确。Google有一个有趣的Robots测试工具,你可以使用。
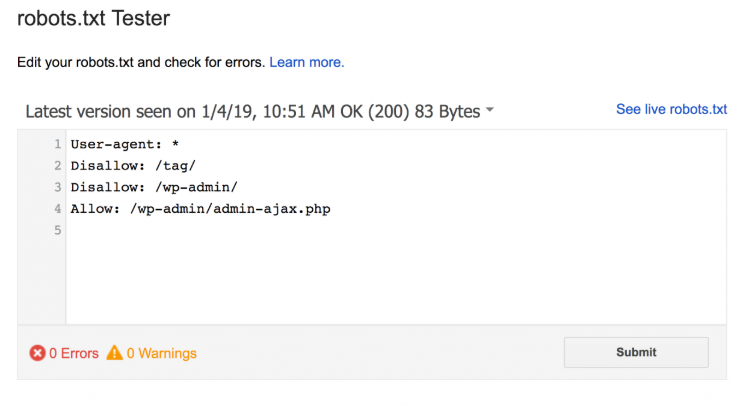
它会显示你的robots.txt文件….以及它发现的任何错误和警告:

如你所见,我们阻止蜘蛛爬行我们的WP管理页面。
我们还使用robots.txt来阻止抓取WordPress自动生成的标签页面(限制重复内容)。
Robots.txt与元指令的对比
当你可以用 “noindex “meta标签在页面级阻止页面时,为什么要使用robots.txt?
就像我之前提到的,noindex标签在多媒体资源上实现起来很麻烦,比如视频和PDF。
另外,如果你有成千上万的页面想被屏蔽,有时用robots.txt来屏蔽整个网站的所有页面,比手动添加noindex标签更容易。
也有一些边缘情况,你不想浪费任何抓取预算,让谷歌在有noindex标签的页面上着陆,这也是边缘情况。
话虽如此。
在这三种边缘情况之外,我建议使用meta指令而不是robots.txt。它们更容易实现。而且致命作物发生的几率也比较小(比如屏蔽了你的整个网站)。
原文:https://backlinko.com/hub/seo/robots-txt
原创文章,作者:图帕先生,感谢支持原创,如若转载,请注明出处:https://www.yestupa.com/seo-robots-txt.html
 微信咖啡
微信咖啡  支付宝咖啡
支付宝咖啡 